

10-k8s实战-深入Pod
深入Pod
Pod配置文件
1 | apiVersion: v1 # api 文档版本 |
探针
容器内应用的监测机制,根据不同的探针来判断容器应用当前的状态
类型
StartupProbe
k8s 1.16 版本新增的探针,用于判断应用程序是否已经启动了。
当配置了 startupProbe 后,会先禁用其他探针,直到 startupProbe 成功后,其他探针才会继续。
作用:由于有时候不能准确预估应用一定是多长时间启动成功,因此配置另外两种方式不方便配置初始化时长来检测,而配置了
statupProbe 后,只有在应用启动成功了,才会执行另外两种探针,可以更加方便的结合使用另外两种探针使用。
1 | startupProbe: |
LivenessProbe
用于探测容器中的应用是否运行,如果探测失败,kubelet 会根据配置的重启策略进行重启,若没有配置,默认就认为容器启动成功,不会执行重启策略。
1 | livenessProbe: |
ReadinessProbe
用于:否健康,它的返回值如果返回 success,那么就认为该容器已经完全启动,并且该容器是可以接收外部流量的。
1 | readinessProbe: |
探测方式
ExeAction
在容器内部执行一个命令,如果返回值为 0,则任务容器时健康的。
1 | livenessProbe: |
TCPSocketAction
通过 tcp 连接监测容器内端口是否开放,如果开放则证明该容器健康
1 | livenessProbe: |
HTTPGetAction
生产环境用的较多的方式,发送 HTTP 请求到容器内的应用程序,如果接口返回的状态码在 200~400 之间,则认为容器健康。
1 | livenessProbe: |
参数配置
initialDelaySeconds: 60 # 初始化时间
timeoutSeconds: 2 # 超时时间
periodSeconds: 5 # 监测间隔时间
successThreshold: 1 # 检查 1 次成功就表示成功
failureThreshold: 2 # 监测失败 2 次就表示失败
生命周期
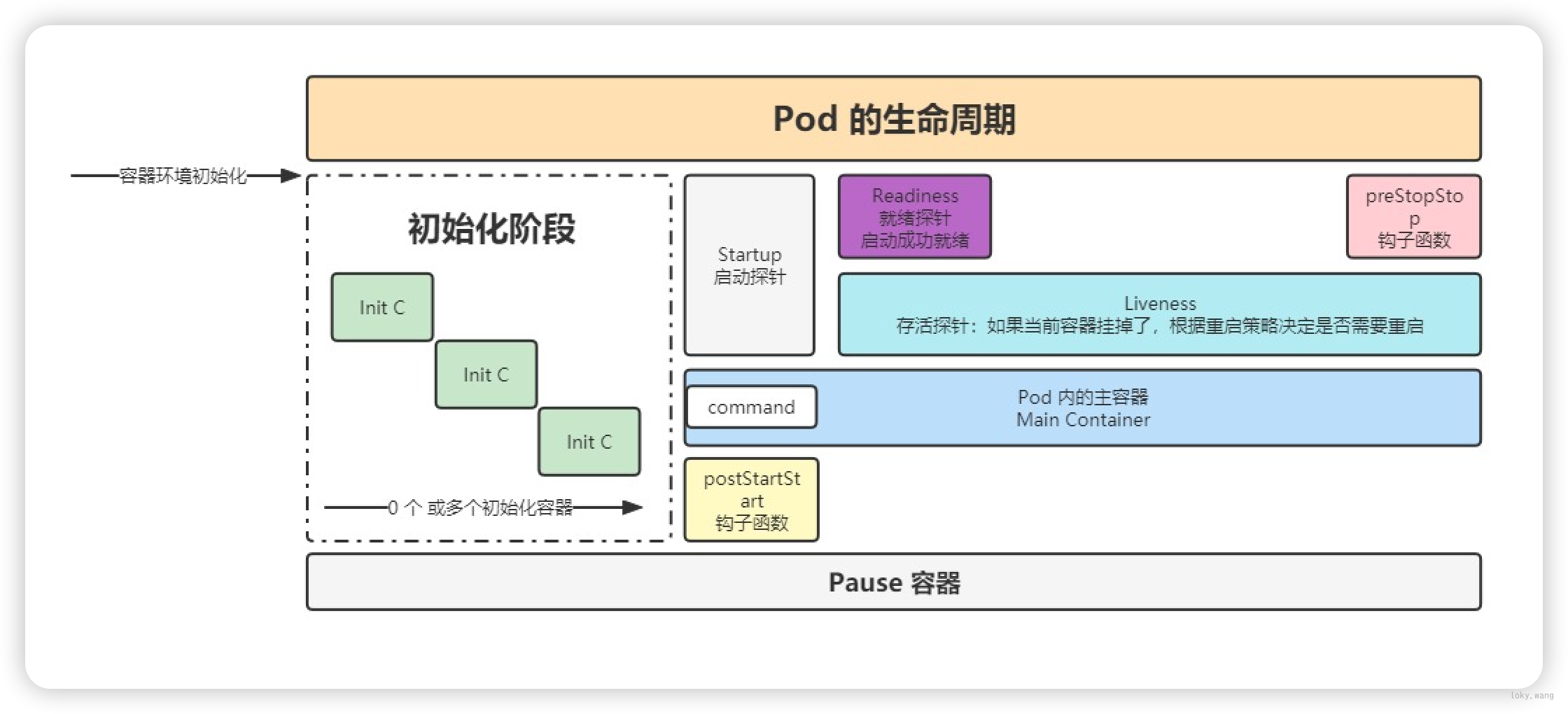
1 | lifecycle: |
Pod退出流程
删除操作
-
Endpoint删除pod的ip地址
-
Pod变成Terminating状态
变为删除中的状态后,会给 pod 一个宽限期,让 pod 去执行一些清理或销毁操作。
配置参数:
1
2
3
4# 作用与 pod 中的所有容器
terminationGracePeriodSeconds: 30
containers:
- xxx -
执行preStop的执行
PreStop的应用
如果应用销毁操作耗时需要比较长,可以在 preStop 按照如下方式进行配置
1 | preStop: |
但是需要注意,由于 k8s 默认给 pod 的停止宽限时间为 30s,如果我们停止操作会超过 30s 时,不要光设置 sleep 50,还要将
terminationGracePeriodSeconds: 30 也更新成更长的时间,否则 k8s 最多只会在这个时间的基础上再宽限几秒,不会真正等待 50s
- 注册中心下线
- 数据清理
- 数据销毁

